AWS Storage Options
The goal of these labs is to demonstrate how we can create a highly durable and available web application, then looking at how we move from a standing charge model, to a pay as use model.
A key part of this is understanding storage options in public cloud providers. One important point is that up until now we have looked at instance based services. EC2 compute instances and RDS databases are based on single virtual machines. If that virtual machine fails, for example because of underlying hardware failure, then that service is lost to you until you restore it, and all ephemeral data on the server or service may also be lost.
However, many public cloud services offer a much higher degree of redundancy. AWS's S3 (Simple Storage Service) holds multiple copies of any object you store in it, such that any two data centres in a region which host your object can fail and the data will still be retained (and you even have the option to copy data between regions for increased redundancy, at the cost of increased latency to synchronise an object between regions).
Understanding the inbuilt redundancy of cloud provider services is an important consideration when designing cloud hosted architectures. It is also important to understand changes in services over time. Since around 2009 objects stored in S3 have benefited from being copied across three availability zones. However, over time AWS have introduced S3 reduced redundancy storage which copies data across two availability zones for lower cost storage, and an express zone option which holds data in a single availability zone for dramatically improved read / write speeds.
So in the next lab sessions we will look at using three different types of AWS storage and how we might use them in an architecture.
S3 - Simple Storage Service
S3 was arguably the first service launched by AWS as a public cloud provider in 2006. At its most basic level it provides a way to store, manage and delete data objects over the HTTP protocol.
We are now going to look at S3 and its use as an object store managed by http get and put.
It is important to note that while services like S3 are object storage systems they do not behave like traditional operating system filesystems, they typically do not support modify after create, file append, file locking, fine grained access controls etc. There are ways you can mount S3 as a filesystem from a compute instance but treat with caution.
Unlike the other storage options we will look at, the permissions for S3 access are determined by the AWS Identity and Access Management service rather than the host operating system
Because it is based on HTTP, S3 storage can also be used directly as a high performance webserver and a backend for a Web Content Delivery Network. We will look at these concepts later but for now we will use it to store objects.
Setting Up S3
Go to the S3 service / tab in the AWS Console. Make sure that you have the "Europe (Ireland)" region selected in the top left.
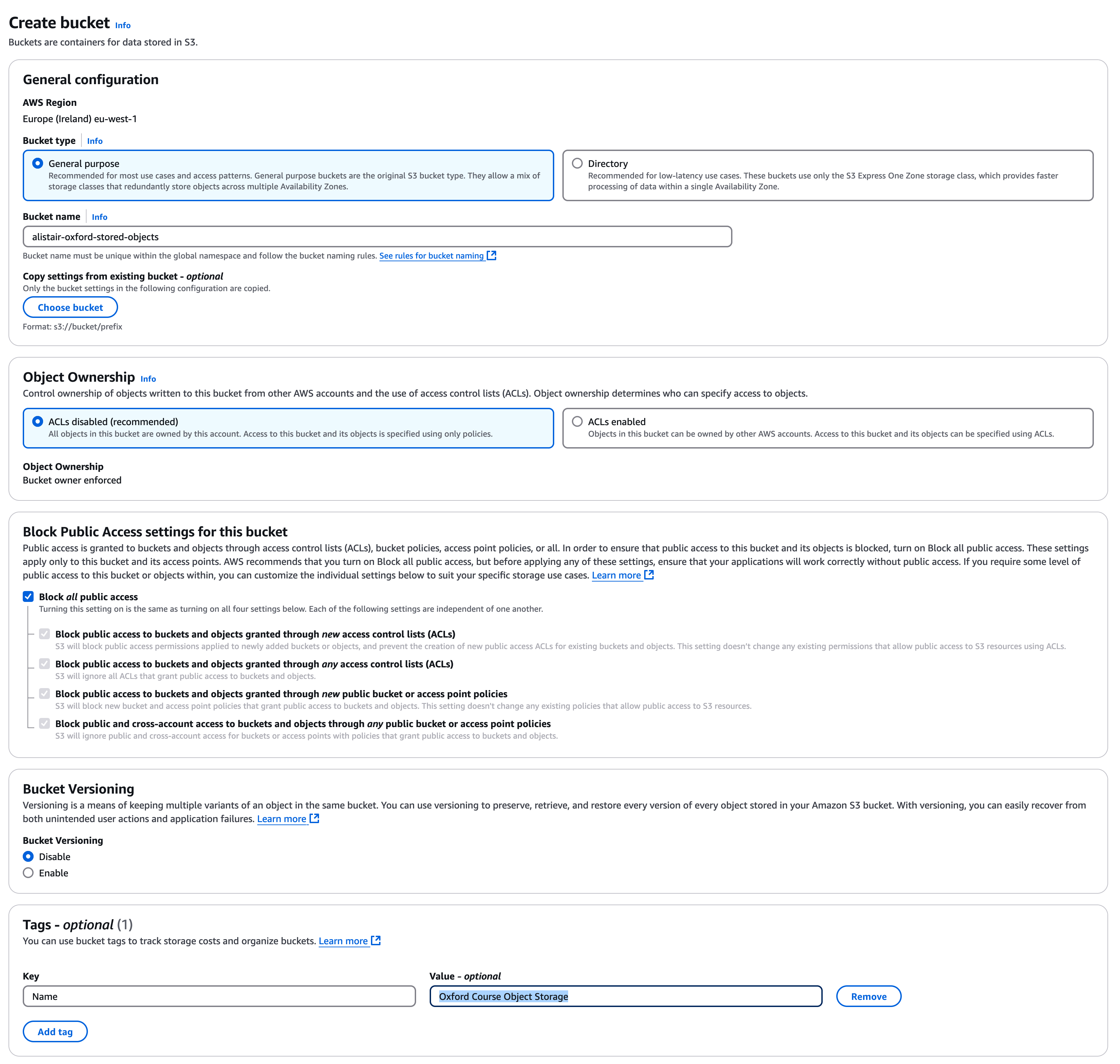
We are going to start by creating a top level bucket. Buckets are containers for your objects and are a boundary for the namespace and several security controls.
In the S3 console, ensure "General Purpose Buckets" are selected and select "Create Bucket"
Select "General Purpose Buckets"
We need to give it a name which is unique among all buckets in S3, I have called mine "alistair-oxford-internal-files", for naming convention keep the"-oxford-internal-files" suffix but use use your own name and you may need to add some numbers to make the name unique.
For Object Ownership leave as "ACLs Disabled"
Under "Block Public Access for this bucket", ensure "Block all Public Access" is selected
Under versioning select "disable". This is useful if you have an architecture which updates objects with newer versions, and you wish to keep history, but that’s not what we want to do today.
Under tags you might want to set a tag of "Name" and "Oxford Course Object Storage"
For default encryption you are safe to leave as "Server-side encryption with Amazon S3 managed keys (SSE-S3)", we would change this for highly restricted data but as we are using public data the default setting is fine.
We don’t need to change "Advanced Settings" so we can go ahead and click "Create Bucket"
You should now see the bucket in your list of buckets
To test security and demonstrate different use cases, we are going to create a second bucket using the same process as above. To distinguish them use the word public in this bucket name e.g. "alistair-oxford-public-files"
Record both the names of the buckets in your scratchpad.
Adding Content to S3
We can now start adding files to the bucket. Initially we are just going to add some images to the bucket so we can test upload and download.
Using your local web browser do an image search for images relating to cloud and computing and download four of them to a folder on your local machine. Don’t choose very large images, but anything which looks like a good website illustration will work well. You might want to give them descriptive names as you download them, and to make life easier remove any spaces from the filename
You should now have a local folder like this;
Now go back to the S3 console and start selecting these files for upload
In the bucket you just created with the name "...oxford-internal-files", select the "Upload" button.
Select the files you downloaded and select "Upload", you shouldn’t need to change any other settings. If all has gone to plan you should see something like this
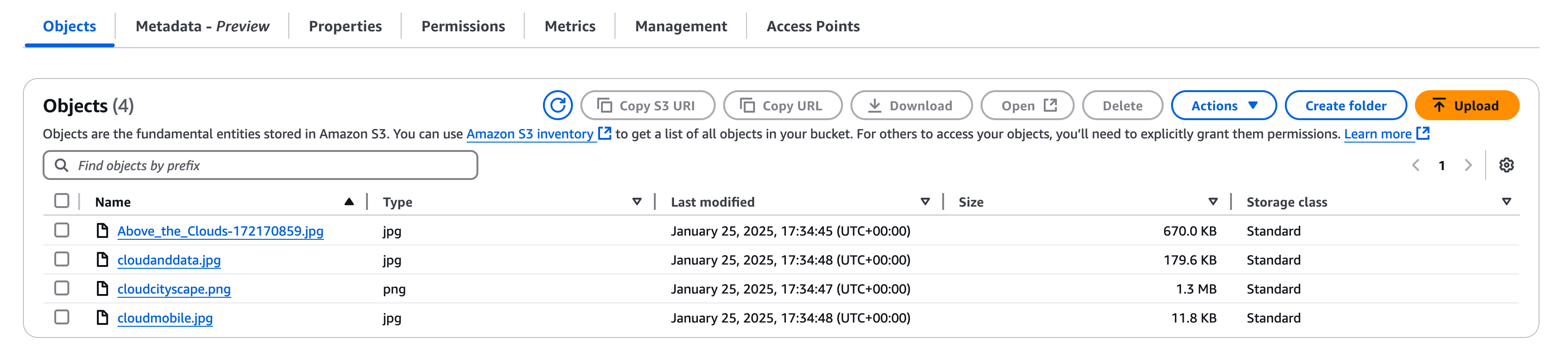
You can click on any file to see its properties and then on "Open" to view the image.
Accessing S3 from your EC2 instances
S3 can be a useful storage option for managing data from any location on the Internet. However, in our cloud architectures it has an important role to play as a durable and regional (multiple availability zone) storage service for our compute instances. Remember that our compute instances are single entities and can fail at any time. But S3 is a managed service distributed across many independent data centres which can be used as a durable service for our ephemeral compute instances to manage their persistent data.
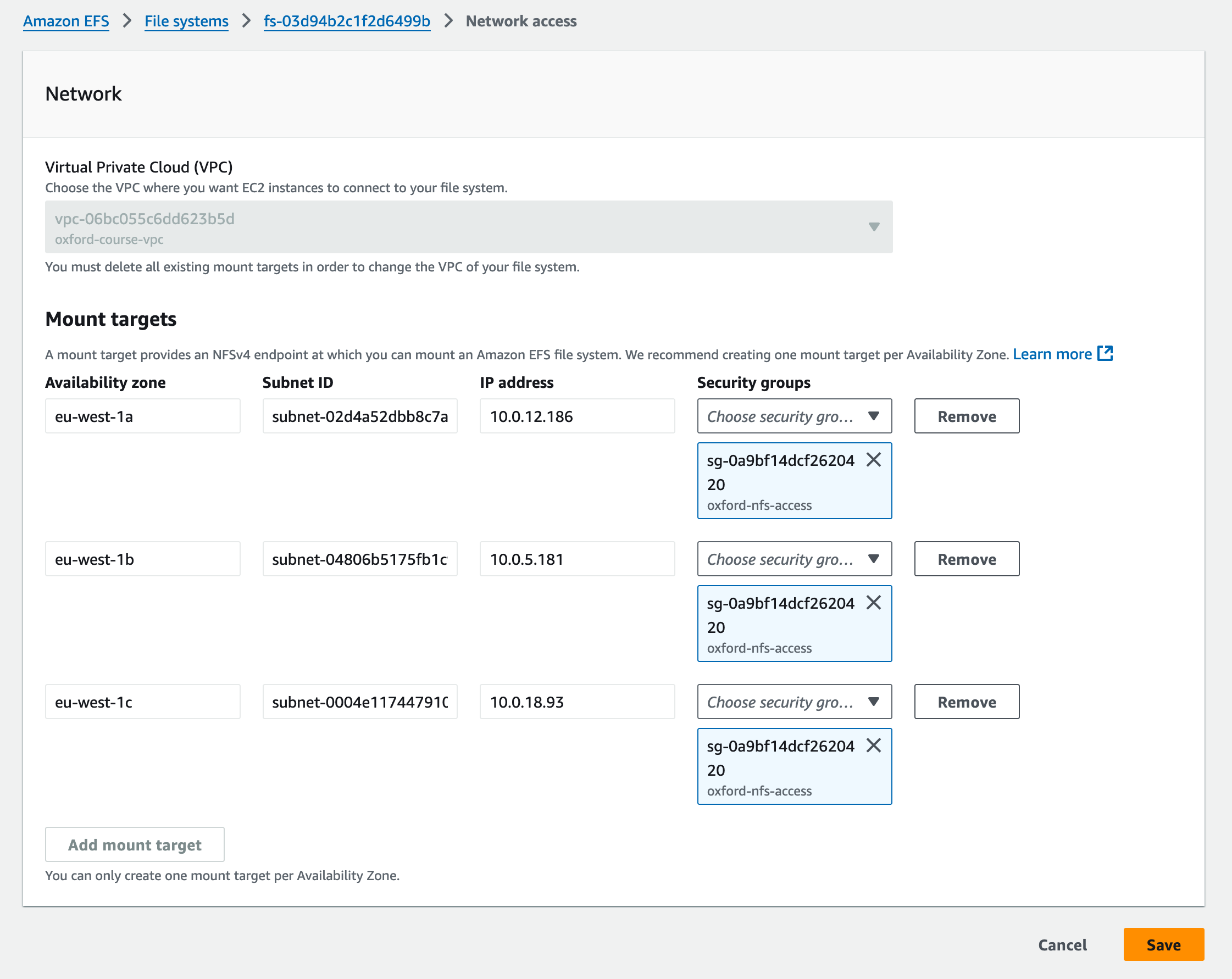
To do this we have to enable access from our instances to S3. For our instances with Internet access they could just use the Internet gateway on the network to access S3. However it is more secure to create an S3 endpoint in our VPC and then restrict access to our bucket to traffic from that endpoint. This means we don't have to open routes to te Internet for our private instances, and we don't have to allow access to our files from anywhere other than our VPC.
We will draw this on the whiteboard, but to do this we will create 3 things
- An S3 endpoint in our VPC to allow traffic from the VPC to S3 (and update the route table)
- An S3 bucket IAM (Identity and Access Management) policy which only allows access from that VPC endpoint
- An IAM role for our EC2 instances which grants S3 API calls access to the bucket.
Preparation
Before we start we will need two pieces of reference data, the ARN for our S3 internal bucket and the VPC ID for our VPC
Go to the S3 console and select the internal bucket you just created. There is a button in the top right labelled "Copy ARN" (see below) - select this then paste the value this to your scratchpad under S3 bucket ARN.

Secondly we will need the VPC Endpoint ID
Go to the VPC console and select your Endpoints, make sure that "Europe (Ireland)" is still selected in the top right of the console as this does get reset sometimes.
You should see an endpoint called something like "oxford-course-vpce-s3".
Select this and under details you should see an Endpoint ID called something like it should look like "vpce-0bba964dd088996a8". Again copy this to your scratchpad under VPC.


Really Important
Make sure you copy the VPC S3 ENDPOINT ID - it must begin with the letters "vpce" or the next step will break
In the example above the value is "vpce-0e27d45e432158468"
Modifying the S3 Bucket Access Policy
First we will allow access to the bucket from authenticated access in the VPC
The AWS guide to this is here - https://docs.aws.amazon.com/AmazonS3/latest/userguide/example-bucket-policies-vpc-endpoint.html
Go to the S3 console and select your bucket e.g. "alistair-oxford-internal-files"
Click on "Permissions" and go to "Bucket Policy"
Click "Edit" and enter the text below;
Warning
Change "alistair-oxford-stored-files" to the bucket name you copied to the scratchpad under S3 Bucket ARN
Change "vpce-0e27d45e432158468" to the VPC Endpoint ID you copied to the scratchpad under VPC S3 Bucket ARN
This policy explicitly denies any s3 API call ( captured in the line "Action": "s3:*" ) if the source VPC endpoint is NOT the VPC endpoint we have defined as part of our VPC.
Note that this policy does not explicitly allow access from the VPC, it states that access from anywhere else will be denied. In the AWS IAM model the first time a deny statement is matched it is enforced, even if other conditions are met.
Note that once the policy is applied you will also lose access to the bucket from the web console, by design. Because of the way S3 bucket policies are implemented, it is possible to lock your account out of a bucket. This is why the "root" account is retained to overwrite these errors.
Note - we are only going to do this for one of our buckets, the other we will leave with more open access permissions
Creating an S3 VPC endpoint
When we created the VPC with the VPC creation wizard we created a default S3 endpoint in our VPC network. However, this is created with a S3 access policy which allows access to any S3 operation on any AWS account, giving us a high risk of data infiltration / exfiltration.
To combat this we will write a policy to restrict access to just the bucket we created
After this we need to ensure route tables are mapped to the S3 endpoint
Go to the VPC Console - In the "Private Link and Lattice Menu" select "Endpoints" - then select your "oxford-course-vpce-s3" endpoint
Select Route tables in the tabs and click on the button "Manage Route Tables"

Ensure all the subnets are clicked for the route table association (they should be called "oxford-course-public..." and "oxford-course-private...") , then click "Modify Route Tables"
This will ensure that every EC2 instance can access S3 via the endpoint.
Next we are going to modify the policy of the endpoint to restrict access to reading and writing files from our bucket
Still on the endpoint screen, click on the tab marked policy
You should see a default policy statement of the form;
{
"Version": "2008-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": "*",
"Action": "*",
"Resource": "*"
}
]
}
This allows any access to any S3 operation with no conditions (although conditions are applied by the S3 bucket policy and User IAM policy). It would be best practice to modify this so the VPC can only access the resources needed by the application.
Click "Edit Policy" and select "Custom", then enter the policy below, replacing the bucket names in bold with the names of the two buckets you created.
This policy allows all S3 buckets in the account to be listed. It then allows the contents of the public and private buckets to be listed and objects to be written and read from them.
Click "Save" and the policy will be applied to the endpoint.
Creating an Instance IAM policy
Finally we need to give our EC2 instances a role which allows them to access S3.
Go to the IAM Console
Go to "Access Management" and Select "Roles" in the left hand menu
Select "Create Role"
Using the Policy Editor, under "Select a Service" select "S3".
Do not select "All S3 actions"
Start by Selecting "ListAllMyBuckets" in the List section and "GetBucketLocation" in the Read section. For "Resources" leave "All" checked.
Now click "+ Add more permissions"
Under List select "ListBucket". Then under resources ensure "specific" is checked and enter the exact bucket names for each of your two buckets to generate the ARN
Now click "+ Add more permissions" and we will add the final permissions.
Under Read select "GetObject" and under Write select "PutObject". Then under resources ensure "specific" is checked and enter the exact bucket names for each of your two buckets, for resource object name check "Any object name" then check "Add ARNs".
Once these details are all entered click "Next"
For Name call the Policy "oxford-vpc-to-s3-bucket-access". For description add some text describing that this policy gives access from the oxford-course-vpc to the two S3 buckets you granted permissions to.
Under permissions defined in this policy you can click on the "S3" Link to see more details on the permissions.
You should now be done, select "Create policy"
Once the policy is created we can review it to see if the format is correct. Find the policy in the console then in the Permissions tab, select the JSON Radio Button.
The policy should look like the below (although the bucket names will be unique to you)
Having Created a Policy, the final step is to create a Role for our EC2 instances to assume
Creating an Instance IAM Role
In broad terms, a policy is an explicit set of permissions related to a service or set of services whereas a role is a function to be performed which may have multiple policies attached. However, this logic is very user defined and it is down to architecture and implementation as to how you wish to manage this
In this case we are going to define a role of "oxford role for EC2 to S3 management". We will attach this to EC2 instance to allow them to access S3 with a specific set of permissions
Still in the IAM console, under "Roles" click on "Create Role".
For "Trusted entity type" select "AWS Service", under Use case select "EC2" then choose "EC2 - Allows EC2 instances to call AWS services on your behalf.", click "Next"
Now you will add the permissions policy we created earlier. In the "filter by type" drop down select "customer managed", you should now see the "oxford-vpc-to-s3-bucket-access" policy you just created. Select it and click "next"
For the role name call it "oxford-role-for-EC2-to-S3-management". That should be the only thing we need to edit on this page, click "Create role".
We now have a role we can attach to our EC2 compute instances to allow them to access two specific S3 buckets.
S3 Access Testing
The steps below were relatively complex so it is worth etsing by clicking the button below and fixing any issues before we move on to the next section.
- Testing S3 Bucket Creation
- Testing S3 Bucket Permissions
- Testing the S3 Bucket Access Policy
- Testing the S3 VPC Endpoint
- Testing the VPC Route Table
- Testing the EC2 Instance IAM Policy
- Testing the EC2 Instance IAM Role
Summary
We have now created
- Two S3 buckets which by default can only be accessed by authenticated IAM users in this AWS account with IAM permissions to access the buckets.
- An S3 bucket access policy which additionally restricts access to one of the S3 buckets from the VPC endpoint
- A VPC endpoint policy allowing access to two of the S3 buckets from the VPC.
- An EC2 role which, when attached to EC instances in our account, allows them to access these two specific buckets.
Warning!
There is a very significant chance that you will have made an error in one of the 4 - 5 steps we have taken to link a compute instance to the S3 object storage service.
It is very tempting to change permissions to be wide open on the bucket and the IAM policy / role so that everything works
However, once you have done this correctly a few times, it will become second nature and you will benefit from a far more secure environment
As you build out production environments these tasks are normally bundled together using a CLI or Python script or using IaaS deployment tools such as Terraform, Pulumi or AWS CloudFormation
Testing S3 Access
Go to the EC2 console and list your instances
Select your webserver instance and in the instance actions menu in the top right select "Security" then "Modify IAM Role"
Choose the role you created earlier e.g. "oxford-EC2-to-S3-full-access"
Select "Update IAM Role"
There is one last action we need to take. At present the security group we created won't allow the webserver to make outbound HTTPS connections outside core subnets, so we need to edit this for the CLI tool to work
In the EC2 Console, under "Networks and Security" select "Security Groups"
Select the Group called "oxford-web-server" then select the "Outbound Rules" tab
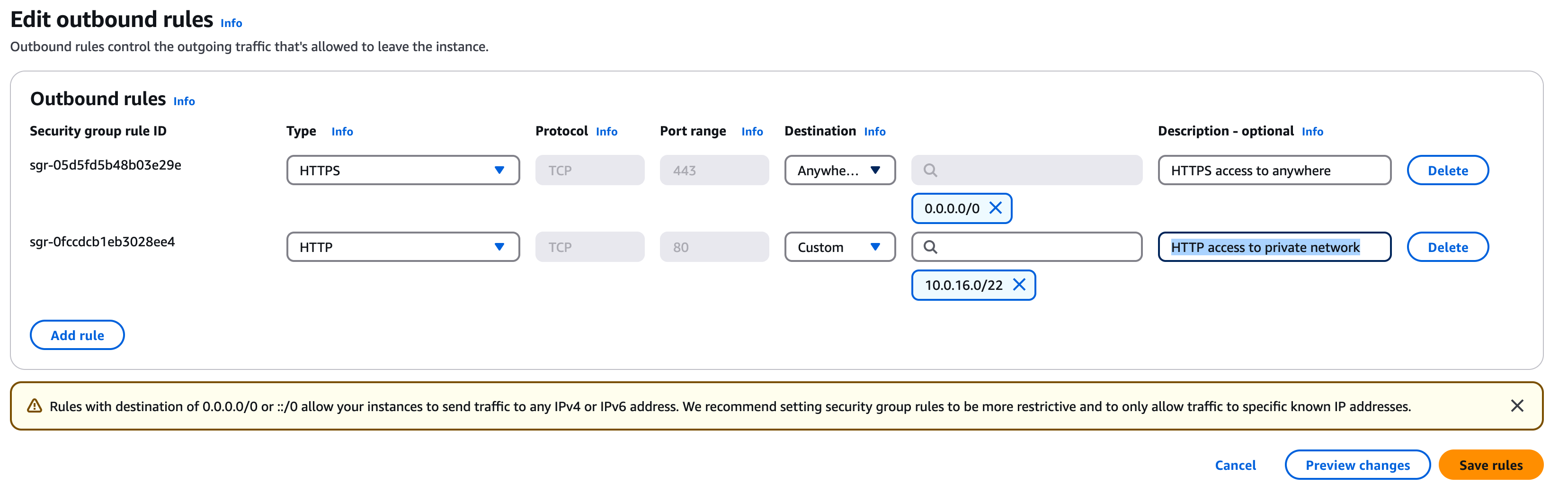
Click the rule for HTTPS, then click "Edit outbound rules"
Under "HTTPS" change the destination to "Anywhere IPv4" and the description to "HTTPS access to anywhere". It should look like the image below
Now you should be able to log into your webserver instance and read and write from your S3 bucket.
Log in to your webserver instance, from the command line ""ssh web"
First we can test reading the bucket
List your buckets with "aws s3 ls"
You should see something like
[ec2-user@ip-10-0-10-4 ~]$ aws s3 ls 2024-12-31 15:46:56 alistair-oxford-stored-files
Then list the contents of the bucket with
"aws s3 ls s3://(your-bucket-name)" (substituting your bucket name here)
e.g.
[ec2-user@ip-10-0-10-4 ~]$ aws s3 ls s3://alistair-oxford-stored-files 2024-12-31 14:11:55 183924 cloudanddata.jpg 2024-12-31 14:11:55 1336299 cloudcityscape.png 2024-12-31 14:11:55 12100 cloudmobile.jpg 2024-12-31 14:11:54 66665 sunrise.jpg
Assuming all this has worked we can use this in conjunction with our webserver
Change to the webserver content directory
"cd /var/www/html/"
To save permission problems we will run the following commands as root, so execute "sudo su"
Then create a new images directory with "mkdir /var/www/html/images"
Change to this directory "cd images"
Now we can download the files from the S3 bucket using the "s3 sync" command
"aws s3 sync s3://(my-bucket-name) ."
change (my-bucket-name) to the name of your s3 bucket, note the important trailing space and full stop
e.g.
[root@ip-10-0-10-4 images]# aws s3 sync s3://alistair-oxford-stored-files . download: s3://alistair-oxford-stored-files/sunrise.jpg to ./sunrise.jpg download: s3://alistair-oxford-stored-files/cloudmobile.jpg to ./cloudmobile.jpg download: s3://alistair-oxford-stored-files/cloudanddata.jpg to ./cloudanddata.jpg download: s3://alistair-oxford-stored-files/cloudcityscape.png to ./cloudcityscape.png [root@ip-10-0-10-4 images]# ls cloudanddata.jpg cloudcityscape.png cloudmobile.jpg sunrise.jpg
Finally make a note of one of the file names, we are going to edit the homepage to include an image
Change to the webserver homepage "cd /var/www/html/"
Edit "index.html" with vi or nano
Change the file as shown below, changing the text in bold to the filename of one of your images
<br>Save the file.
When you reload you should have a cloudy image below your transaction list. This really isn't going to win ay design awards but we'll create a nicer homepage in the later labs.
S3 and Server Builds
We can use data in S3 to run EC2 image builds
To achieve this we can use a cloud-init script which runs as we launch a server
The steps are as follows;
- Copy the binaries we need into an S3 bucket
- Create a server start up script which copies the data from this bucket
- Start a server with the S3 access role and a start up scripts
- Test the running webserver
This is one way to build a server. We could even expand using a build service like Puppet or Ansible to run a more complex build as the server is launched. We can now discuss the benefit of using immutable images from a pipeline (Netflix approach), combining an enhanced base with on boot config or build or a full pets approach using services like system center and patch manager to maintain a longer lived image.
S3 Conclusion
We have demonstrated that we can connect to S3 from our compute instances in a VPC using a private gateway and secure the gateway and the target bucket.
Although this seemed like a lot to configure in the security course we will look at the potentially serious consequences of getting this wrong.
This is important when we think of our compute instances as ephemeral or disposable units of compute. We want to be able to create and destroy them quickly in response to changing demand, or replace them if the cloud provider infrastructure causes them to fail.
We could do this by baking the website content into the base image that we build every instance from. But this is inflexible if we want to update our site content frequently.
So an alternative mechanism is that we use S3 sync to frequently have each compute instance poll S3 for the website content and update on their own filesystem. This doesn't just work for websites but batch processing, grid compute and a range of use cases.
Another important point to note is that webservers generate important data in the form of logs. These could be lost if we rely on ephemeral compute storage. But if we save them in 10 second or one minute chunks and transfer them to S3 we both reduce the need for local storage on the compute instances, we also have the data stored on cheaper but highly durable storage for later analysis.